 常用ASCII码对照表
常用ASCII码对照表
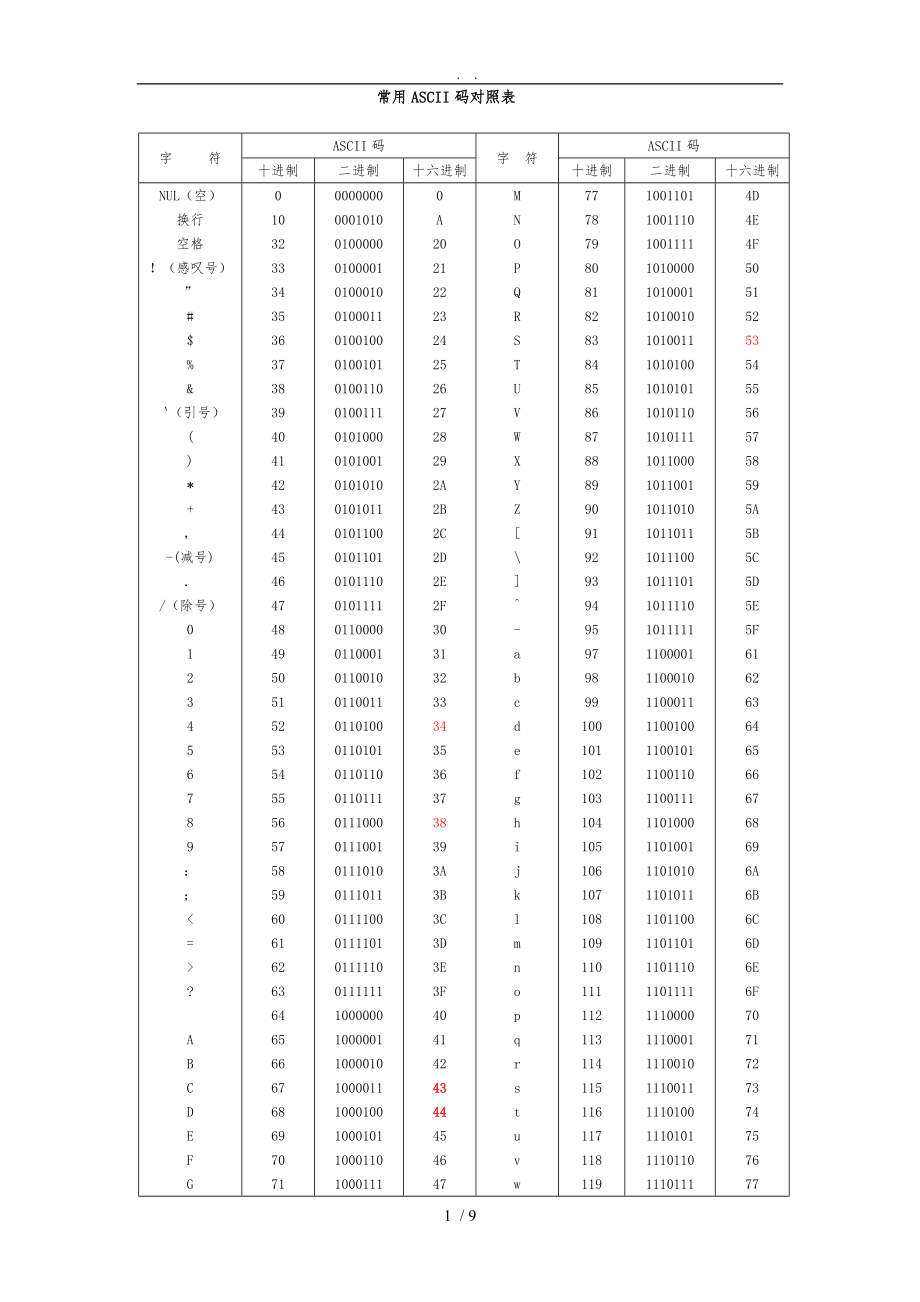

《常用ASCII码对照表》由会员分享,可在线阅读,更多相关《常用ASCII码对照表(9页珍藏版)》请在装配图网上搜索。
1、 . . 常用ASCII码对照表字 符ASCII码字符ASCII码十进制二进制十六进制十进制二进制十六进制NUL(空)换行空格!(感叹号)”#$%&(引号)()*+,-(减号)/(除号)0123456789:;?ABCDEFGHIJKL01032333435363738394041424344454647484950515253545556575859606162636465666768697071727374757600000000001010010000001000010100010010001101001000100101010011001001110101000010100101010
2、1001010110101100010110101011100101111011000001100010110010011001101101000110101011011001101110111000011100101110100111011011110001111010111110011111110000001000001100001010000111000100100010110001101000111100100010010011001010100101110011000A202122232425262728292A2B2C2D2E2F303132333435363738393A3B3C
3、3D3E3F404142434445464748494A4B4CMNOPQRSTUVWXYZ-abcdefghijklmnopqrstuvwxyz77787980818283848586878889909192939495979899100101102103104105106107108109110111112113114115116117118119120121122123125100110110011101001111101000010100011010010101001110101001010101101011010101111011000101100110110101011011101
4、110010111011011110101111111000011100010110001111001001100101110011011001111101000110100111010101101011110110011011011101110110111111100001110001111001011100111110100111010111101101110111111100011110011111010111101111111014D4E4F505152535455565758595A5B5C5D5E5F6162636465666768696A6B6C6D6E6F70717273747
5、5767778797A7B7D字 符ASCII码字符ASCII码十进制二进制十六进制十进制二进制十六进制1. ASCII码 在计算机部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。ASCII码一共规定了128个字符的编码,比如空格“
6、SPACE”是32(十进制的32,用二进制表示就是00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。2、非ASCII编码英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。但是,这里又出现了新的问题。不同的国家
7、有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了,在希伯来语编码中却代表了字母Gimel (),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0127表示的符号是一样的,不一样的只是128255的这一段。至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。3.Unicode正如上一节所说,世界上存在着多种编
8、码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。解释:同一个文本文件,假设容是用英语写的,在英语编码的情况下,每个字符会和一个二进制数对应(如00101000类似),然后存到计算机中,这时把这个英语文件发给一个俄语国家的用户,计算机传输的是二进制流,即0101之类的数据,到了俄语用户这方,需要有它的俄语编码方式进行解码,把每个二进制流转为字符显示,由于俄语编码表中对每串二进制流数据的解释方式不同,同一个数据如00101000在英语中可能
9、代表A,而在俄语中则代表B,这样就会产生乱码,这是我个人的理解。GB2312编码、日文编码等也是非unicode编码,是要通过转换表(codepage)转换成unicode编码的,要不怎么显示出来呢?可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可
10、以查询unicode.org,或者专门的汉字对应表。4. Unicode的问题需要注意的是,Unicode只是一个符号集,只是一种规、标准,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储在计算机上。比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(0101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表
11、示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法承受的。它们造成的结果是:1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。2)unicode在很长一段时间无法推广,直到互联网的出现。5.UTF-8互联网的普与,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是U
12、nicode的实现方式之一,它规定了字符如何在计算机中存储、传输等。UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用14个字节表示一个符号,根据不同的符号而变化字节长度。UTF-8的编码规则很简单,只有二条:1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。2)对于n字节的符号(n1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提与的二进制位,全部为这个符号的unicode码。下表总结了编码规则,字母x表示可用编码的位。Unicode符号围 | UT
13、F-8编码方式(十六进制) | (二进制)-+-0000 0000-0000 007F | 0#x0000 0080-0000 07FF | 110#x 10#0000 0800-0000 FFFF | 1110# 10# 10#0001 0000-0010 FFFF | 11110#x 10# 10# 10#下面,还是以汉字“严”为例,演示如何实现UTF-8编码。已知“严”的unicode是4E25(0101),根据上表,可以发现4E25处在第三行的围(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110# 10# 10#”。然后,从“严”的最
14、后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,这是保存在计算机中的实际数据,转换成十六进制就是E4B8A5,转成十六进制的目的为了便于阅读。6. Unicode与UTF-8之间的转换通过上一节的例子,可以看到“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。在Windows平台下,有一个最简单的转化方法,就是使用置的记事本小程序Notepad.exe。打开文件后,点击“文件”菜单中的“另存为”命令,会跳出一个对话框,在最
15、底部有一个“编码”的下拉条。里面有四个选项:ANSI,Unicode,Unicode big endian 和 UTF-8。1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。2)Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的little endian格式。3)Unicode big endian编码与上一个选项相对应。我在下一节会解释little endian和big endian的涵义。4)UTF-8编码,也就是上一节谈到的编
16、码方法。选择完”编码方式“后,点击”保存“按钮,文件的编码方式就立刻转换好了。7. Little endian和Big endian上一节已经提到,Unicode码可以采用UCS-2格式直接存储。以汉字”严“为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?Unicode规中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行
17、空格“(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。8. 实例下面,举一个实例。打开”记事本“程序Notepad.exe,新建一个文本文件,容就是一个”严“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8编码方式保存。然后,用文本编辑软件UltraEdit中的”十六进制功能“,观察该文件的部编码方式。1)ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的GB
18、2312编码,这也暗示GB2312是采用大头方式存储的。2)Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”说明是小头方式存储,真正的编码是4E25。3)Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE FF”说明是大头方式存储。4)UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的。推荐这篇文章看一下:wiki.ubuntu.org/index.php?title=Unicode&
19、variant=zh-cn#.E8.B5.B7.E6.BA.90.E8.88.87.E7.99.BC.E5.B1.959.解决的问题:一、如何在中文系统中运行非Unicode编码程序?有很多意大利文版(除英文版)学习软件、百科全书等软件在中文系统上会出现乱码,解决方法: WindowsXP核是Unicode编码,支持多语种,对于Unicode编码的应用程序会正常显示原文(因为windows核心是用unicode代码写的,所以不存在问题),但是,很多程序不是用Unicode编码写的,这时WindowsXP系统可以指定以特定的编码运行非Unicode编码程序,中文版WindowsXP默认的是“简体
20、中文GB2312”。你只需在控制面板-区域和语言选项-高级-为非Unicode程序的语言选择“意大利语”,即可正确运行意大利文版的游戏程序。分析:我理解的流程是这样:程序-意大利语编码(转换表codepage)-解释成unicode识别的编码(通过指定的转换表将非 Unicode 的字符编码转换为同一字符对应的系统部使用的 Unicode 编码)-被系统翻译成意大利文(因为每个unicode编码对应了相应的意大利文字),便可以正常显示了。二、消除网页乱码?网页乱码是浏览器对HTML网页解释时形成的,如果网页制作时编码为繁体big5,浏览器却以编码gb2312显示该网页,就会出现乱码,因此只要你
21、在浏览器中也以繁体big5显示该网页,就会消除乱码。打个比方有些像字典,繁体字得用繁体字典来查看,简体字得用简体字典来查看,不然你看不懂。 解决方法:在浏览器中选择“编码”菜单,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样当浏览网页出现乱码时,即可手工更改查看此网页的编码方式,在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其他语言依此类推,便可消除网页乱码现象。 分析:因为繁体big5编码后的文件,每个文字对应一个二进制流(假设是1212对应繁这个字),当
22、我们以编码gb2312显示该网页时,gb2312编码会到表里去找1212(二进制流不会变的)对应谁,肯定不再是繁这个字了,当然显示的就不再是那个繁字了,也就会出现乱码了。这样理解简单些,其实中间还要转换成同一字符对应的系统部使用的 Unicode 编码,然后通过系统底层unicode编码还原成相应字符显示出来。推荐两个编码查询:1.nengcha./code/ascii/ 2.bm.kdd.cc/ASCII 非打印控制字符ASCII 表上的数字 031 分配给了控制字符,用于控制像打印机等一些外围设备。例如,12 代表换页/新页功能。此命令指示打印机跳到下一页的开头。 ASCII 非打印控制字
23、符表 十进制十六进制字符十进制十六进制字符000空1610数据链路转意101头标开始1711设备控制 1202正文开始1812设备控制 2303正文完毕1913设备控制 3404传输完毕2014设备控制 4505查询2115反确认606确认2216同步空闲707震铃2317传输块完毕808backspace2418取消909水平制表符2519媒体完毕100A换行/新行261A替换110B竖直制表符271B转意120C换页/新页281C文件分隔符130D回车291D组分隔符140E移出301E记录分隔符150F移入311F单元分隔符ASCII 打印字符数字 32126 分配给了能在键盘上找到的字
24、符,当您查看或打印文档时就会出现。数字 127 代表 DELETE 命令。 ASCII 打印字符表 十进制十六进制字符十进制十六进制字符3220space8050P3321!8151Q34228252R3523#8353S3624$8454T3725%8555U3826&8656V39278757w4028(8858X4129)8959Y422A*905AZ432B+915B442C,925C452D-935D462E.945E472F/955F_483009660493119761a503229862b513339963c5234410064d5335510165e5436610266f55
25、37710367g5638810468h5739910569i583A:1066Aj593B;1076Bk603C1106En633F?1116Fo644011270p6541A11371q6642B11472r6743C11573s6844D11674t6945E11775u7046F11876v7147G11977w7248H12078x7349I12179y744AJ1227Az754BK1237B764CL1247C|774DM1257D784EN1267E794FO1277FDEL扩展ASCII打印字符扩展的ASCII字符满足了对更多字符的需求。扩展的 ASCII 包含 ASCII
26、中已有的 128 个字符(数字 032 显示在以下图中),又增加了 128 个字符,总共是 256 个。即使有了这些更多的字符,许多语言还是包含无法压缩到 256 个字符中的符号。因此,出现了一些 ASCII 的变体来囊括地区性字符和符号。 例如,许多软件程序把 ASCII 表(又称作 ISO 8859-1)用于北美、西欧、澳大利亚和非洲的语言。 扩展的ASCII 打印字符表 十进制十六进制字符十进制十六进制字符12880192C012981193C113082194C213183195C313284196C413385197C513486198C613587199C713688200C813
27、789201C91388A202CA1398B203CB1408C204CC1418D205CD1428E206CE1438F207CF14490208D014591209D114692210D214793211D314894212D414995213D515096214D615197215D715298216D815399217D91549A218DA1559B219DB1569C220DC1579D221DD1589E222DE1599F223DF160A0224E0161A1225E1162A2226E2163A3227E3164A4228E4165A5229E5166A6230E616
28、7A7231E7168A8232E8169A9233E9170AA234EA171AB235EB172AC236EC173AD237ED174AE238EE175AF239EF176B0240F0177B1241F1178B2242F2179B3243F3180B4244F4181B5245F5182B6246F6183B7247F7184B8248F8185B9249F9186BA250FA187BB251FB188BC252FC189BD253FD190BE254FE191BF255FF10101010AA 0001100018取消000011000C换页/新页10100110A6 11001010CA11100101E50101010054 T001100013110101010155U010011004CL0010010125%0101001153S11000101C50101010054 T10110001B10001000111设备控制 1AAAA 1818取消0C0C换页/新页A6A6 CACAE5E55454 T313115555U4C4CL2525%1B1B转意0101头标开始9 / 9
- 温馨提示:
1: 本站所有资源如无特殊说明,都需要本地电脑安装OFFICE2007和PDF阅读器。图纸软件为CAD,CAXA,PROE,UG,SolidWorks等.压缩文件请下载最新的WinRAR软件解压。
2: 本站的文档不包含任何第三方提供的附件图纸等,如果需要附件,请联系上传者。文件的所有权益归上传用户所有。
3.本站RAR压缩包中若带图纸,网页内容里面会有图纸预览,若没有图纸预览就没有图纸。
4. 未经权益所有人同意不得将文件中的内容挪作商业或盈利用途。
5. 装配图网仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对用户上传分享的文档内容本身不做任何修改或编辑,并不能对任何下载内容负责。
6. 下载文件中如有侵权或不适当内容,请与我们联系,我们立即纠正。
7. 本站不保证下载资源的准确性、安全性和完整性, 同时也不承担用户因使用这些下载资源对自己和他人造成任何形式的伤害或损失。
