 数据库安全机制
数据库安全机制

《数据库安全机制》由会员分享,可在线阅读,更多相关《数据库安全机制(28页珍藏版)》请在装配图网上搜索。
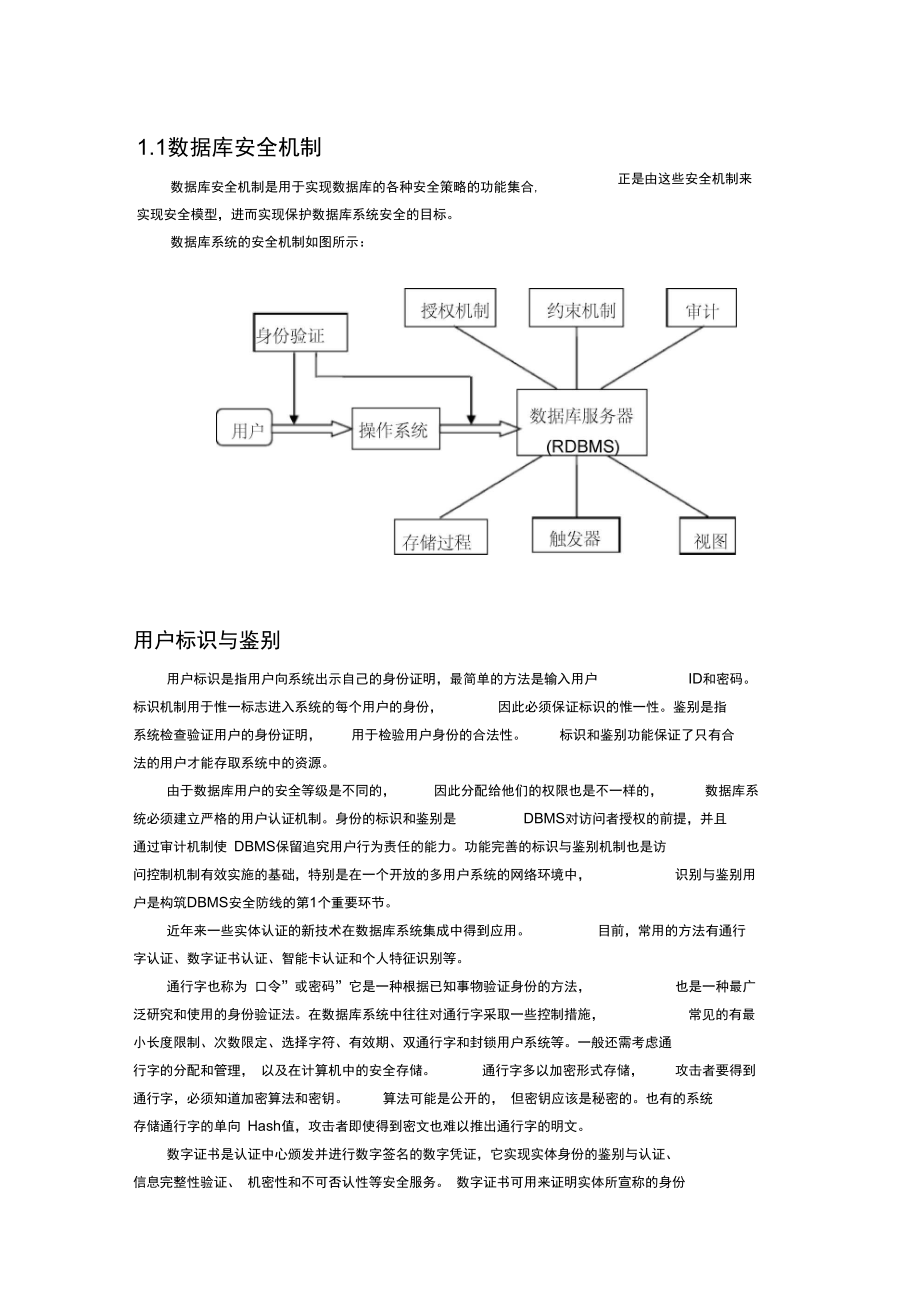
1、1.1数据库安全机制正是由这些安全机制来数据库安全机制是用于实现数据库的各种安全策略的功能集合, 实现安全模型,进而实现保护数据库系统安全的目标。数据库系统的安全机制如图所示:用户标识与鉴别用户标识是指用户向系统出示自己的身份证明,最简单的方法是输入用户ID和密码。标识机制用于惟一标志进入系统的每个用户的身份,因此必须保证标识的惟一性。鉴别是指系统检查验证用户的身份证明,用于检验用户身份的合法性。标识和鉴别功能保证了只有合法的用户才能存取系统中的资源。由于数据库用户的安全等级是不同的,因此分配给他们的权限也是不一样的,数据库系统必须建立严格的用户认证机制。身份的标识和鉴别是DBMS对访问者授权
2、的前提,并且通过审计机制使 DBMS保留追究用户行为责任的能力。功能完善的标识与鉴别机制也是访 问控制机制有效实施的基础,特别是在一个开放的多用户系统的网络环境中,识别与鉴别用户是构筑DBMS安全防线的第1个重要环节。近年来一些实体认证的新技术在数据库系统集成中得到应用。目前,常用的方法有通行字认证、数字证书认证、智能卡认证和个人特征识别等。通行字也称为 口令”或密码”它是一种根据已知事物验证身份的方法,也是一种最广泛研究和使用的身份验证法。在数据库系统中往往对通行字采取一些控制措施,常见的有最小长度限制、次数限定、选择字符、有效期、双通行字和封锁用户系统等。一般还需考虑通 行字的分配和管理,
3、 以及在计算机中的安全存储。通行字多以加密形式存储,攻击者要得到通行字,必须知道加密算法和密钥。算法可能是公开的, 但密钥应该是秘密的。也有的系统存储通行字的单向 Hash值,攻击者即使得到密文也难以推出通行字的明文。数字证书是认证中心颁发并进行数字签名的数字凭证,它实现实体身份的鉴别与认证、 信息完整性验证、 机密性和不可否认性等安全服务。 数字证书可用来证明实体所宣称的身份 与其持有的公钥的匹配关系,使得实体的身份与证书中的公钥相互绑定。智能卡(有源卡、 IC 卡或 Smart 卡)作为个人所有物,可以用来验证个人身份,典型 智能卡主要由微处理器、 存储器、输入输出接口、 安全逻辑及运算处
4、理器等组成。 在智能卡 中引入了认证的概念,认证是智能卡和应用终端之间通过相应的认证过程来相互确认合法 性。在卡和接口设备之间只有相互认证之后才能进行数据的读写操作, 目的在于防止伪造应 用终端及相应的智能卡。根据被授权用户的个人特征来进行确证是一种可信度更高的验证方法, 目前已得到应用 的个人生理特征包括指纹、语音声纹( voice- print )、DNA 、视网膜、虹膜、脸型和手型等。1.1.2 访问控制1.1.2.1 概述访问控制的目的是确保用户对数据库只能进行经过授权的有关操作。在存取控制机制 中,一般把被访问的资源称为 “客体 ”,把以用户名义进行资源访问的进程、 事务等实体称为
5、“主体”。传统的存取控制机制有两种, 即 DAC( Discretionary Access Control ,自主存取控制) 和 MAC (Mandatory Access Control ,强制存取控制) 。近年来, RBAC ( Role-based Access Control, 基于角色的存取控制)得到了广泛的关注。1.1.2.2 数据访问级别和类型DBMS 中的安全系统必须具有伸缩性以便为各种数据级别授权。数据级别有以下几种: 整个数据库、单个关系表(所有行和所有列) 、关系表中特定列(所有行) 、关系表中的特定 行(所有列)以及关系表的特定行和特定列。数据的所有访问模式和类型如下
6、:插入或建立。在文件中添加数据,不销毁任何数据。 读取。用户可通过应用程序或数据库查询,将数据从数据库复制到用户环境。 更新。编写更新值。删除。删除和销毁特定数据库对象。 移动。移动数据对象,但没有读取内容的权限。 执行。使用执行需要的权限,运行程序或过程。 确认存在性。确认数据库是否存在特定数据库对象。1.1.2.3 任意控制( DAC )采用该方法以若干种指派模式授予各个用户访问特定数据项的权限或权力。基于权限 说明, 用户能以读取、更新、插入或删除模式随意访问数据项。建立数据库对象的用户自动 得到此对象的所有访问权限,包括将此对象的权限再授予他人。在授予或撤消访问权限时,有两种主要级别:
7、 数据库对象:数据项或数据元素,一般是基本表或视图用户:可以用一些授权标识符识别的单个用户或用户组授权通常都是在这两种级别上进行。1. 授权DBMS提供了功能强大的授权机制,它可以给用户授予各种不同对象(表、视图、存储过程等)的不同使用权限(如Select、update、insert、delete等)。在用户级别,可以授予数据库模式和数据操纵方面的以下几种授权,包括:创建和删除索引、创建新关系、添加或删除关系中的属性、删除关系、查询数据、插入新数据、修改数 据、删除数据等。在数据库对象级别,可将上述访问权限应用于数据库、基本表、视图和列等。2. 数据库角色如果要给成千上万个雇员分配许可,将面临
8、很大的管理难题,每次有雇员到来或者离开时,就得有人分配或去除可能与数百张表或视图有关的权限。这项任务很耗时间而且非常容易出错。即使建立 SQL过程来帮忙,也几乎需要时时去维护。一个相对特别简单有效的 解决方案就是定义数据库角色。数据库角色是被命名的一组与数据库操作相关的权限,角色是一组相关权限的集合。因此,可以为一组具有相同权限的用户创建一个角色,使用角色来管理数据库权限可以简化授权的过程。先创建一个角色,并且把需要的许可分配给角色,而不是分配给个人用户,然后再把角色分配给特定用户。当有新的雇员到来时,把角色添加给用户就提供了所有必要的权限。授权管理机制如图4-3所示。用户用户 用户用户强制控
9、制(MAC)强制访问控制模型基于与每个数据项和每个用户关联的安全性标识(Security Label)。安全性标识被分为若干级别:绝密(Top Secret)、机密(Secret)、秘密 (Confidential)、一般(Public)。数据的标识称为密级 (Security Classification),用户的标识称为许可级别证 (Security Cleara nee)。在计算机系统中,每个运行的程序继承用户的许可证级别,也可以说,用户的许可证 级别不仅仅应用于作为人的用户,而且应用于该用户运行的所有程序。当某一用户以某一密级进入系统时,在确定该用户能否访问系统上的数据时应遵守如下规则
10、:当且仅当用户许可证级别大于等于数据的密级时,该用户才能对该数据进行读操作。操作。第二条规则表明用户可以为其写入的数据对象赋予高于自己许可证级别的密级,这样 的数据被写入后用户自己就不能再读该数据对象了。这两种规则的共同点在于它们禁止了拥有高级许可证级别的主体更新低密级的数据对象,从而防止了敏感数据的泄露。1.125基于角色的存取控制(RBAC)RBAC在主体和权限之间增加了一个中间桥梁 一一角色。权限被授予角色,而管理员通 过指定用户为特定角色来为用户授权。从而大大简化了授权管理,具有强大的可操作性和可管理性。角色可以根据组织中的不同工作创建,然后根据用户的责任和资格分配角色,用户可以轻松地
11、进行角色转换。而随着新应用和新系统的增加,角色可以分配更多的权限,也可以根据需要撤销相应的权限。RBAC核心模型包含了5个基本的静态集合,即用户集(users)、角色集(roles)、特权集 (perms)(包括对象集(objects)和操作集(operators),以及一个运行过程中动态维 护的集合,即会话集(sessions),如图1-1所示。用户集包括系统中可以执行操作的用户,是主动的实体;对象集是系统中被动的实体,包含系统需要保护的信息;操作集是定义在对象上的一组操作,对象上的一组操作构成了一个特权;角色则是 RBAC模型的核心,通过用户分配(UA )和特权分配(PA)使用户与特 权关
12、联起来。RBAC属于策略中立型的存取控制模型,既可以实现自主存取控制策略,又可以实现强制存取控制策略。它可以有效缓解传统安全管理处理瓶颈问题,被认为是一种普遍适用的访问控制模型,尤其适用于大型组织的有效的访问控制机制。1.126视图机制几乎所有的DBMS都提供视图机制。视图不同于基本表,它们不存储实际数据,数据库表存储数据,视图好象数据库表的窗口,是虚拟表。当用户通过视图访问数据时,是从基本表获得数据,但只是由视图中定义的列构成。视图提供了一种灵活而简单的方法,以个人化方式授予访问权限,是强大的安全工具。在授予用户对特定视图的访问权限时,该权限只用于在该视图中定义的数据项,而未用于完整基本表本
13、身。 因此,在使用视图的时候不用担心用户会无意地删除数据或者给真实表中添加有害的数据,并且可以限制用户只能使用指定部分的数据,增加了数据的保密性和安全性。1.1.3 数据库加密1.1.3.1 概述由于数据库在操作系统中以文件形式管理, 所以入侵者可以直接利用操作系统的漏洞窃 取数据库文件,或者篡改数据库文件内容。另一方面,数据库管理员( DBA )可以任意访 问所有数据,往往超出了其职责范围,同样造成安全隐患。因此, 数据库的保密问题不仅包 括在传输过程中采用加密保护和控制非法访问, 还包括对存储的敏感数据进行加密保护, 使 得即使数据不幸泄露或者丢失, 也难以造成泄密。 同时, 数据库加密可
14、以由用户用自己的密 钥加密自己的敏感信息, 而不需要了解数据内容的数据库管理员无法进行正常解密, 从而可 以实现个性化的用户隐私保护。对数据库加密必然会带来数据存储与索引、 密钥分配和管理等一系列问题, 同时加密也 会显著地降低数据库的访问与运行效率。 保密性与可用性之间不可避免地存在冲突, 需要妥 善解决二者之间的矛盾。数据库中存储密文数据后, 如何进行高效查询成为一个重要的问题。 查询语句一般不可以直 接运用到密文数据库的查询过程中,一般的方法是首先解密加密数据,然后查询解密数据。 但由于要对整个数据库或数据表进行解密操作, 因此开销巨大。 在实际操作中需要通过有效 的查询策略来直接执行密
15、文查询或较小粒度的快速解密。一般来说,一个好的数据库加密系统应该满足以下几个方面的要求。 足够的加密强度,保证长时间且大量数据不被破译。 加密后的数据库存储量没有明显的增加。 加解密速度足够快,影响数据操作响应时间尽量短。 加解密对数据库的合法用户操作(如数据的增、删、改等)是透明的。 灵活的密钥管理机制,加解密密钥存储安全,使用方便可靠。1.1.3.2 数据库加密的实现机制数据库加密的实现机制主要研究执行加密部件在数据库系统中所处的层次和位置, 通过 对比各种体系结构的运行效率、可扩展性和安全性,以求得最佳的系统结构。 按照加密部件与数据库系统的不同关系, 数据库加密机制可以从大的方面分为库
16、内加密和库 外加密。(1)库内加密库内加密在 DBMS 内核层实现加密,加解密过程对用户与应用透明,数据在物理存 取之前完成加解密工作。这种方式的优点是加密功能强,并且加密功能集成为 DBMS 的 功能,可以实现加密功能与 DBMS 之间的无缝耦合。对于数据库应用来说,库内加密方式 是完全透明的。库内加密方式的主要缺点如下。 对系统性能影响比较大, BMS 除了完成正常的功能外,还要进行加解密运算,从而加重了数据库服务器的负载。 密钥管理风险大, 加密密钥与库数据保存在服务器中, 其安全性依赖于 DBMS 的访问控 制机制。 加密功能依赖于数据库厂商的支持, DBMS 一般只提供有限的加密算法
17、与强度可供选择, 自主性受限。(2)库外加密 在库外加密方式中,加解密过程发生在 DBMS 之外, DBMS 管理的是密文。加解 密过程大多在客户端实现,也有的由专门的加密服务器或硬件完成。与库内加密方式相比,库外加密的明显优点如下。 由于加解密过程在客户端或专门的加密服务器实现,所以减少了数据库服务器与 DBMS 的运行负担。 可以将加密密钥与所加密的数据分开保存,提高了安全性。 由客户端与服务器的配合,可以实现端到端的网上密文传输。 库外加密的主要缺点是加密后的数据库功能受到一些限制,例如加密后的数据无法正常索 引。同时数据加密后也会破坏原有的关系数据的完整性与一致性, 这些都会给数据库应
18、用带 来影响。在目前新兴的外包数据库服务模式中, 数据库服务器由非可信的第三方提供, 仅用来运行标 准的 DBMS ,要求加密解密都在客户端完成。1.1.3.3 数据库加密的粒度一般来说,数据库加密的粒度可以有 4 种,即表、属性、记录和数据元素。不同加密粒 度的特点不同, 总的来说,加密粒度越小,则灵活性越好且安全性越高,但实现技术也更为 复杂,对系统的运行效率影响也越大。(1)表加密 表级加密的对象是整个表, 这种加密方法类似于操作系统中文件加密的方法。 即每个表 与不同的表密钥运算, 形成密文后存储。 这种方式最为简单, 但因为对表中任何记录或数据 项的访问都需要将其所在表的所有数据快速
19、解密, 因而执行效率很低, 浪费了大量的系统资 源。在目前的实际应用中,这种方法基本已被放弃。(2)属性加密属性加密又称为 “域加密 ”或“字段加密 ”,即以表中的列为单位进行加密。一般而言,属 性的个数少于记录的条数, 需要的密钥数相对较少。 如果只有少数属性需要加密, 属性加密 是可选的方法。(3)记录加密 记录加密是把表中的一条记录作为加密的单位,当数据库中需要加密的记录数比较少 时,采用这种方法是比较好的。(4)数据元素加密数据元素加密是以记录中每个字段的值为单位进行加密, 数据元素是数据库中最小的加 密粒度。采用这种加密粒度,系统的安全性与灵活性最高,同时实现技术也最为复杂。 不同
20、的数据项使用不同的密钥, 相同的明文形成不同的密文, 抗攻击能力得到提高。 不利的方面 是,该方法需要引入大量的密钥。 一般要周密设计自动生成密钥的算法, 密钥管理的复杂度 大大增加,同时系统效率也受到影响。在目前条件下, 为了得到较高的安全性和灵活性, 采用最多的加密粒度是数据元素。 为 了使数据库中的数据能够充分而灵活地共享,加密后还应当允许用户以不同的粒度进行访 问。1.1.3.4 加密算法加密算法是数据加密的核心, 一个好的加密算法产生的密文应该频率平衡, 随机无重码, 周期很长而又不可能产生重复现象。 窃密者很难通过对密文频率, 或者重码等特征的分析获 得成功。同时,算法必须适应数据
21、库系统的特性,加解密,尤其是解密响应迅速。常用的加密算法包括对称密钥算法和非对称密钥算法。对称密钥算法的特点是解密密钥和加密密钥相同, 或解密密钥由加密密钥推出。 这种算 法一般又可分为两类, 即序列算法和分组算法。 序列算法一次只对明文中的单个位或字节运 算;分组算法是对明文分组后以组为单位进行运算,常用有 DES 等。非对称密钥算法也称为 “公开密钥算法 ”,其特点是解密密钥不同于加密密钥, 并且从解 密密钥推出加密密钥在计算上是不可行的。 其中加密密钥公开, 解密密钥则是由用户秘密保 管的私有密钥。常用的公开密钥算法有 RSA 等。目前还没有公认的专门针对数据库加密的加密算法, 因此一般
22、根据数据库特点选择现有 的加密算法来进行数据库加密。 一方面,对称密钥算法的运算速度比非对称密钥算法快很多, 二者相差大约 23 个数量级; 另一方面, 在公开密钥算法中, 每个用户有自己的密钥对。 而 作为数据库加密的密钥如果因人而异, 将产生异常庞大的数据存储量。 因此, 在数据库加密 中一般采取对称密钥的分组加密算法。1.1.3.5 密钥管理对数据库进行加密, 一般对不同的加密单元采用不同的密钥。 以加密粒度为数据元素为 例,如果不同的数据元素采用同一个密钥,由于同一属性中数据项的取值在一定范围之内, 且往往呈现一定的概率分布, 因此攻击者可以不用求原文, 而直接通过统计方法即可得到有
23、关的原文信息,这就是所谓的统计攻击。大量的密钥自然会带来密钥管理的问题。 根据加密粒度的不同, 系统所产生的密钥数量 也不同。越是细小的加密粒度, 所产生的密钥数量越多, 密钥管理也就越复杂。良好的密钥 管理机制既可以保证数据库信息的安全性, 又可以进行快速的密钥交换, 以便进行数据解密。对数据库密钥的管理一般有集中密钥管理和多级密钥管理两种体制, 集中密钥管理方法 是设立密钥管理中心。 在建立数据库时, 密钥管理中心负责产生密钥并对数据加密, 形成一 张密钥表。当用户访问数据库时,密钥管理机构核对用户识别符和用户密钥。通过审核后, 由密钥管理机构找到或计算出相应的数据密钥。 这种密钥管理方式
24、方便用户使用和管理, 但 由于这些密钥一般由数据库管理人员控制,因而权限过于集中。目前研究和应用比较多的是多级密钥管理体制, 以加密粒度为数据元素的三级密钥管理 体制为例, 整个系统的密钥由一个主密钥、 每个表上的表密钥, 以及各个数据元素密钥组成。 表密钥被主密钥加密后以密文形式保存在数据字典中, 数据元素密钥由主密钥及数据元素所 在行、 列通过某种函数自动生成,一般不需要保存。在多级密钥体制中,主密钥是加密子系 统的关键,系统的安全性在很大程度上依赖于主密钥的安全性。1.1.3.6 数据库加密的局限性数据库加密技术在保证安全性的同时,也给数据库系统的可用性带来一些影响。(1)系统运行效率受
25、到影响数据库加密技术带来的主要问题之一是影响效率。 为了减少这种影响, 一般对加密的范 围做一些约束,如不加密索引字段和关系运算的比较字段等。(2)难以实现对数据完整性约束的定义数据库一般都定义了关系数据之间的完整性约束, 如主外键约束及值域的定义等。 数 据一旦加密, DBMS 将难以实现这些约束。(3)对数据的 SQL 语言及 SQL 函数受到制约SQL语言中的Group by、Order by及Having子句分别完成分组和排序等操作,如果这 些子句的操作对象是加密数据, 那么解密后的明文数据将失去原语句的分组和排序作用。 另 外, DBMS 扩展的 SQL 内部函数一般也不能直接作用于
26、密文数据。(4)密文数据容易成为攻击目标加密技术把有意义的明文转换为看上去没有实际意义的密文信息,但密文的随机性同时也暴露了消息的重要性, 容易引起攻击者的注意和破坏, 从而造成了一种新的不安全性。 加 密技术往往需要和其他非加密安全机制相结合,以提高数据库系统的整体安全性。数据库加密作为一种对敏感数据进行安全保护的有效手段,将得到越来越多的重视。 总体来说,目前数据库加密技术还面临许多挑战, 其中解决保密性与可用性之间的矛盾是关键。1.1.4 审计“审计” 功能是 DBMS 达到 C2 以上安全级别必不可少的一项指标。 因为任何系统的安 全措施都是不完美的, 蓄意盗窃、 破坏数据的人总是想方
27、设法打破控制。 审计通常用于下列 情况:审查可疑的活动。 例如:当出现数据被非授权用户所删除、 用户越权操作或权限管 理不正确时, 安全管理员可以设置对该数据库的所有连接进行审计, 和对数据库中所有表的 操作进行审计。监视和收集关于指定数据库活动的数据。例如: DBA 可收集哪些表经常被修改、 用户执行了多少次逻辑 I/O 操作等统计数据,为数据库优化与性能调整提供依据。对 DBA 而言,审计就是记录数据库中正在做什么的过程。审计记录可以告诉你正在使 用哪些系统权限,使用频率是多少, 多少用户正在登录, 会话平均持续多长时间, 正在特殊 表上使用哪些命令,以及许多其他有关事实。审计能帮助 DB
28、A 完成的操作类型包括: 为管理程序准备数据库使用报表 (每天 /周连接多少用户,每月发出多少查询,上周 添加或删除了多少雇员记录 )。如果怀疑有黑客活动,记录企图闯入数据库的失败尝试。 确定最繁忙的表,它可能需要额外的调整。调查对关键表的可疑更改。 从用户负载方面的预期增长,规划资源消耗。审计功能把用户对数据库的所有操作自动记录下来放入审计日志( Audit Log )中。审 计日志一般包括下列内容:操作类型(如修改、查询等) 。 操作终端标识与操作人员标识。操作日期和时间。 操作的数据对象(如表、视图、记录、属性等) 。 数据修改前后的值。DBA 可以利用审计跟踪的功能,重现导致数据库现状
29、的一系列事件,找出非法存取数 据的人、时间和内容等。审计通常比较费时间和空间,所以 DBMS 往往都将其作为可选特 征,允许 DBA 根据应用对安全性的要求,灵活地打开或关闭审计功能。审计功能一般主要 用于安全性要求较高的部门。审计一般可以分为用户级审计和系统级审计。 用户级审计是任何用户可设置的审计, 主要是 针对自己创建的数据库或视图进行审计,记录所有用户对这些表或视图的一切成功和(或) 不成功的访问要求以及各种类型的 SQL 操作。系统级审计只能由 DBA 设置,用以监测成功 或失败的登录要求、监测 Grant 和 Revoke 操作以及其他数据库级权限下的操作。1.1.5 备份与恢复一
30、个数据库系统总是避免不了故障的发生。 安全的数据库系统必须能在系统发生故障后 利用已有的数据备份, 恢复数据库到原来的状态, 并保持数据的完整性和一致性。 数据库系 统所采用的备份与恢复技术, 对系统的安全性与可靠性起着重要作用, 也对系统的运行效率 有着重大影响。1.1.5.1 数据库备份常用的数据库备份的方法有如下 3 种。(1)冷备份冷备份是在没有终端用户访问数据库的情况下关闭数据库并将其备份,又称为 “脱机备 份”。这种方法在保持数据完整性方面显然最有保障,但是对于那些必须保持每天 24 小时、 每周 7 天全天候运行的数据库服务器来说,较长时间地关闭数据库进行备份是不现实的。2)热备
31、份热备份是指当数据库正在运行时进行的备份, 又称为 “联机备份 ”。因为数据备份需要一 段时间, 而且备份大容量的数据库还需要较长的时间, 那么在此期间发生的数据更新就有可 能使备份的数据不能保持完整性, 这个问题的解决依赖于数据库日志文件。 在备份时, 日志 文件将需要进行数据更新的指令 “堆起来 ”,并不进行真正的物理更新, 因此数据库能被完整 地备份。备份结束后, 系统再按照被日志文件 “堆起来 ”的指令对数据库进行真正的物理更新。 可见,被备份的数据保持了备份开始时刻前的数据一致性状态。热备份操作存在如下不利因素。 如果系统在进行备份时崩溃,则堆在日志文件中的所有事务都会被丢失,即造成
32、数据的 丢失。 在进行热备份的过程中,如果日志文件占用系统资源过大,如将系统存储空间占用完, 会造成系统不能接受业务请求的局面,对系统运行产生影响。 热备份本身要占用相当一部分系统资源,使系统运行效率下降。(3)逻辑备份逻辑备份是指使用软件技术从数据库中导出数据并写入一个输出文件, 该文件的格式一 般与原数据库的文件格式不同, 而是原数据库中数据内容的一个映像。 因此逻辑备份文件只 能用来对数据库进行逻辑恢复, 即数据导入, 而不能按数据库原来的存储特征进行物理恢复。 逻辑备份一般用于增量备份,即备份那些在上次备份以后改变的数据。1.1.5.2 数据库恢复在系统发生故障后, 把数据库恢复到原来
33、的某种一致性状态的技术称为 “恢复 ”,其基本 原理是利用 “冗余 ”进行数据库恢复。 问题的关键是如何建立 “冗余 ”并利用 “冗余”实施数据库 恢复,即恢复策略。数据库恢复技术一般有 3 种策略, 即基于备份的恢复、 基于运行时日志的恢复和基于镜 像数据库的恢复。(1)基于备份的恢复基于备份的恢复是指周期性地备份数据库。 当数据库失效时, 可取最近一次的数据库备 份来恢复数据库, 即把备份的数据拷贝到原数据库所在的位置上。 用这种方法, 数据库只能 恢复到最近一次备份的状态, 而从最近备份到故障发生期间的所有数据库更新将会丢失。 备 份的周期越长,丢失的更新数据越多。(2)基于运行时日志的
34、恢复运行时日志文件是用来记录对数据库每一次更新的文件。 对日志的操作优先于对数据库 的操作, 以确保记录数据库的更改。 当系统突然失效而导致事务中断时, 可重新装入数据库 的副本, 把数据库恢复到上一次备份时的状态。 然后系统自动正向扫描日志文件, 将故障发 生前所有提交的事务放到重做队列, 将未提交的事务放到撤销队列执行, 这样就可把数据库 恢复到故障前某一时刻的数据一致性状态。(3 )基于镜像数据库的恢复数据库镜像就是在另一个磁盘上复制数据库作为实时副本。当主数据库更新时,DBMS自动把更新后的数据复制到镜像数据,始终使镜像数据和主数据保持一致性。当主库出现故障时,可由镜像磁盘继续提供使用
35、,同时DBMS自动利用镜像磁盘数据进行数据库恢复。镜像策略可以使数据库的可靠性大为提高,但由于数据镜像通过复制数据实现,频繁的复制会降低系统运行效率,因此一般在对效率要求满足的情况下可以使用。为兼顾可靠性和可用性,可有选择性地镜像关键数据。数据库的备份和恢复是一个完善的数据库系统必不可少的一部分,目前这种技术已经广泛应用于数据库产品中,如Oracle数据库提供对联机备份、脱机备份、逻辑备份、完全数据恢复及不完全数据恢复的全面支持。据预测,以数据”为核心的计算(Data CentricComput ing)将逐渐取代以 应用”为核心的计算。在一些大型的分布式数据库应用中,多备 份恢复和基于数据中
36、心的异地容灾备份恢复等技术正在得到越来越多的应用。聚合、推理与多实例数据库安全中,用户根据低密级的数据和模式的完整性约束推导出高密级的数据,造成未经授权的信息泄露,其主要有两种方式:推理和聚合。1.1.6.1 聚合(Aggregation )聚合是指这种情形:如果用户没有访问特定信息的权限,但是他有访问这些信息的组成部分的权限。这样,她就可以将每个组成部分组合起来,得到受限访问的信息。用户可以通过不同的途径得到信息,通过综合就可以得到本没有明确访问权限的信息。注意:聚合(Aggregation )指的是组合不同来源的信息的行为。用户没有明确的权 限可以访问组合起来得到的信息, 而组合得到的信息
37、比信息的各个组成部分拥有更高的机密 性。下面是一个简单的概念化例子。假设数据库管理员不想让Users组的用户访问一个特定的句子 “ The chicke n wore fu nny red culottes.” ,他将这个句子分成六个部分,限制用户访问。如图:Component AComponent BComponent CComponent DComponent EComponent FEmily 可以访问 A 、 C、 F 三个部分,由于她是个特别聪明的人,她可以根据这三个部 分结合起来得出这个句子的部分。为了防止聚合,需要防止主体和任何主体的应用程序和进程获得整个数据集合的权限, 包括数
38、据集合的各个独立组成部分。客体可以进行分类并赋予较高的级别,存储在容器中, 防止低级别权限的主体访问。对主体的查询, 可以进行跟踪, 并实施基于上下文的分类。这 将记录主体对客体的访问历史,并在聚合攻击发生时限制访问企图。1.1.6.2 推理 ( Inference )推理( Inference )和聚合很相似。推理指的是主体通过他可以访问的信息推理出受限 访问的信息。当可以由安全级别较低的数据描述出较高级别的数据时,就会发生推理攻击。注意:推理是得到不是显性可用的信息的能力。例如, 如果一个职员不应该知道军队在沙特阿拉伯的行动计划,但是他可以访问到食品需求表格和帐篷位置的文档, 那么他就可以
39、根据食品和帐篷运送的目的地推算出军队正在向 Dubia 地 区 移 动 。 在 文 档 安 全 性 分 类 中 , 食 品 需 求 和 帐 篷 位 置 文 档 是 机 密 文 档 ( Confidential ),而军队行动计划是绝密文档( Top of Secret )。由于不同的分类,这 个职员可以根据他知道的信息推理出他不应该知道的秘密。常见的推理通道有以下 4 种。 执行多次查询,利用查询结果之间的逻辑联系进行推理。用户一般先向数据库发出多个 查询请求,这些查询大多包含一些聚集类型的函数(如合计和平均值等) 。然后利用返回的 查询结果,在综合分析的基础上推断出高级数据信息。 利用不同级
40、别数据之间的函数依赖进行推理分析,数据表的属性之间常见的一种关系是 “函数依赖 ”和“多值依赖 ”。这些依赖关系有可能产生推理通道, 如同一病房的病人患的是同 一种病,以及由参加会议的人员可以推得参与会议的公司等。 利用数据完整性约束进行推理,例如关系数据库的实体完整性要求每一个元组必须有一 个惟一的键。 当一个低安全级的用户想在一个关系中插入一个元组, 并且这个关系中已经存 在一个具有相同键值的高安全级元组,那么为了维护实体的完整性, DBMS 会采取相应的 限制措施。低级用户由此可以推出高级数据的存在,这就产生了一条推理通道。 利用分级约束进行推理。一条分级约束是一条规则,它描述了对数据进
41、行分级的标准。 如果这些分级标准被用户获知的话,用户有可能从这些约束自身推导出敏感数据。一个办法是防止主体或者与主体有关的应用程序和进程间接得到能推论的信息。 在数据 库开发过程中, 可以实施基于内容或者基于上下文的分类规则来解决这个问题, 对主体的查 询请求进行跟踪,限制可以进行推理的查询模式。防止推理攻击的一种措施叫做单元抑制( Cell Suppression ),采用数据库分隔,或 者噪声和扰动。 单元抑制时一种用来隐藏或者不显示特定存储单元的内容, 防止这些信息被 用来进行推理攻击。分隔数据库( Partitioning a database )包括将数据库分成不同的部 分,使未授权
42、用户很难访问到可以用于推理攻击的相关的数据。 噪声和扰动是一种在数据库 中插入伪造信息的技术,目的是为了误导和迷惑攻击者,使得真实的推理攻击不能成功。1.163 多实例(Polyinstantiation )有的时候,不希望低安全级别的用户访问和修改高安全级别的数据。有不同的方法处理这种情况。一种方法是当低级别用户访问高级别数据时,拒绝访问。然而,这就相对于间接告诉访问者他要访问的对象中包含敏感信息。另一种处理方法是多实例(Polyi nsta ntiation)。多实例建立了相同主键的多元组和由安全级别定义的实例之间的关系。当一条信息插入到数据库中时,需要限制低级别用户访问这条信息。通过建立
43、另一组数据迷惑低级别用户,使用户认为他得到的信息是真实的,而不是仅仅限制信息的访问。例如,海军基地有一艘租用Oklahoma 船舶公司从Delaware到Ukraine的运载武器的货船,这种类型的信息应该划为绝密信息(Top of Secret )。只有声明拥有绝密信息权限的人才可以访问。可以创建一个虚假信息文件,内容是Oklahoma 船舶公司有一艘从 Delaware 到非洲的食品货运船,如表11-1。很明显,Oklahoma 的船只已经离开,但是低安全级别的用户以为船去了非洲,而不是到Ukraine 。这就保证低安全级别的用户不去试图过问这艘船的真正使命,他们已经知道这艘船已经没有意义了
44、,而去寻找其它运输武器的船只了。注意:多实例是通过变化值或者其它属性来交互生成客体详细信息的过程。一个为低安全级别用户提供替代信息的多实例(Polyi nsta ntiatio n)例子:LevelShipCaroOriginDestinationTop SecretOklahomaWeaponsDelawareUkiineUnclassifiedOklahomaFoodDelawareAfrica多实例为同一客体创建了两种不同的视图,因此低级别的用户无从知道真正的信息,同时也阻止了他试图进一步以其它途径获得真正的信息。多实例是一种为没有相应安全级别的用户提供替代信息的方法。用MySQL创建数
45、据库和数据表:步骤:1、使用show语句找出在服务器上当前存在什么数据库:mysqlshow databases;hysq;l shoif databases ;l S _ _ io _ i abase!:info i*mat io n _s c he ma : my盘吐L! pe r-f o r-ma.n c e _s c he na !点敦kiL抚! sns! vro i*-ldi1+b rows in set CO.09 sec)2、创建一个数据库test:mysqlcreate database test;epeace ilatAba&e te&t:hwu尸y OK. 1 raw af
46、fected t0.00 書3、选择你所创建的数据库:mysqluse test;.yql u?c test 9 atabas e clianged4创建一个数据表:首先查看刚才创建的数据库中存在什么表:mysqlshow tables;ijisql show tables: ;n讹H set (说明刚才创建的数据库中还没有数据库表) 接着我们创建一个关于students的数据表:包括学生的学号(id),姓名(name),性别(sex),年龄(age)。mysqlcreate table students(id int unsigned not null auto_increment prim
47、ary key,name char(8) not null,sex char(4) not null,age tinyint un sig ned not n ull,);create table studen tsCid int unslgjined not null aut o _in c re men t primairy1 ke Lname char not nullagre tinyint unsigfiied not null)1:OK鼻 0 rows affected C0,3?解释:以 id int unsigned not null auto_increment primar
48、y key行进行介绍:id为列的名称;int指定该列的类型为int(取值范围为-8388608到8388607),在后面我们又用unsigned加以修饰,表示该类型为无符号型,此时该列的取值范围为 0到16777215;not null说明该列的值不能为空,必须要填,如果不指定该属性,默 认可为空;auto_increment需在整数列中使用,其作用是在插入数据时若该列为NULL, MySQL将自动产生一个比现存值更大的唯一标识符值。在每张表中仅能有一个这样的值且所在列必须为索引列。primary key表示该列是表的主键,本列的值必须唯一,MySQL将 自动索引该列。下面的char(8)表示
49、存储的字符长度为8, tinyint的取值范围为-127 到128, default属性指定当该列值为空时的默认值。创建一个表后,用show tables显示数据库中有哪些表:mysqlshow tables;Fiywtll呂ho忡 tables ;klF! Tablcs_in_tcst !+I studentsHI11 row in set 5、显示表结构:mysqldescribe stude nts;mys(il describe stutdents :Q -4-+Flue Idi iT5Pe! Null-I1 im _Keyi _ Defaulti ExtraTTTyid11int u
50、nsigned! NO11FBIl1NULLi auto_increnertname11chap:NO11I lNULL11sex11cli 已 1*(4! NO111lNULL11agre11-+-t in ylnt C9 uns Igrned! NO-+111i-4NULL11勺 rou? in etsec6、在表中添加记录:首先用select命令来查看表中的数据:mysqlselect*from stude nts;ysql select*fron students; mpty set (说明刚才创建的数据库表中还没有任何记录)接着加入一条新纪录:mysqlinsert into stu
51、dents value(01 Tom, 8;_ytql insert into students value; OJG 1 rw effected (6.0? sec再用select命令来查看表中的数据的变化:mysqlselect*from stude nts;selectfIora students;-h-十一-1r-1-7、用文本方式将数据装入一个数据库表:创建一个文本文件“ student.sq”每行包括一个记录,用TAB键把值分开,并且以在createtable语句中列出的次序,例如:02TonyF1803AmyM1804LisaM18将文本文件“ student.sq”装载到stu
52、dents表中:mysqlload data local in file” estude nt.sql into table stude nts;yEql Load data local inf ileMe:XXstudentE_sql*,in-to table students : uery 0K 0 yous affected (0.00 sec)ecords: 3 Deleted: 0 Skipped: 3 Uarninsrs: 0再使用select命令来查看表中的数据的变化:mysqlselect*from stude nts;my寻?eLcct * from students;idi
53、 l-hiIsexage-4-H-1i1TomiIFl1182I ITonyilF111831Anyiltl11184I1Lisa.iInl1185I1iII1R-1-4-pows in set 0_00 sec)1表名抄表记录主键ID序号字段名称字段说明类型位数属性备注1IDIDInt4非空主键,自增2抄表人抄表人Int4非空3目标表目标表Int4非空4抄表时间抄表时间datetime8非空5示数示数float8非空2表名抄表信息主键ID序号字段名称字段说明类型位数属性备注1IDIDInt4非空主键,自增2表名表名n char20可空3表编号表编号n char20可空4所属子站所属子站int
54、4可空5关口表倍率关口表倍率float8非空6电费单价电费单价float8非空7结算方式结算方式n char20可空8计费方式计费方式n char20可空3表名电站关注表主键ID序号字段名称字段说明类型位数属性备注1IDIDInt4非空主键,自增2用户用户Int4非空3电站电站Int4非空4表名电站设备表主键ID序号字段名称字段说明类型位数属性备注1IDIDvarchar50非空主键,自增2设备名称设备名称varchar50非空3所属电站所属电站Int4非空4设备类型设备类型Varchar10非空5父级设备父级设备Varchar50可空6组件数量组件数量int4非空7显示顺序显示顺序int4非
55、空5表名故障表 2021主键ID序号字段名称字段说明类型位数属性备注1IDIDInt4非空主键,自增2子站子站Int4非空3设备编号设备编号n char200非空4故障内容故障内容n char200非空5功率损失功率损失float8非空6故障时间故障时间datetime8非空7恢复时间恢复时间datetime8可空6表名故障表 2021主键ID序号字段名称字段说明类型位数属性备注1IDIDInt4非空主键,自增2子站子站Int4非空3设备编号设备编号n char100非空4故障内容故障内容n char100非空5功率损失功率损失float8非空6故障时间故障时间datetime8非空7恢复时间
56、恢复时间datetime8可空7表名故障工单表主键ID序号字段名称字段说明类型位数属性备注1IDIDInt4非空主键,自增2工单号工单号Varchar32非空3故障类型故障类型n char20非空4上报时间上报时间datetime8非空5上报人上报人int4可空6发现时间发现时间datetime8非空7故障说明故障说明n char200非空8故障位置n char40非空9所在巡视点Int4可空10接单人int4可空11操作指导n char200可空12是否现场处理bit1非空13是否处理完成bit1非空14完成时间datetime8可空15所属子站int4非空16图片image16可空17外部
57、文件nv archar-1可空18处理说明nv archar100可空19关联故障int4可空8表名集团信息表主键ID序号字段名称字段说明类型位数属性备注1ID集团IDInt4非空主键,自增2集团编号集团编号nchar100非空3集团名称集团名称nchar100非空4集团地址集团地址nchar100可空5在建装机容量在建装机容 量deci mal5非空6在建电站数量在建电站数 量int4非空7未建装机容量未建装机容量deci mal5非空8未建电站数量未建电站数量Int4非空9父集团ID父集团IDint4可空9表名角色权限表主键SIDELINEID序号字段名称字段说明类型位数属性备注1IDIDInt4非空主键,自增2所属角色所属角色Int4非空3权限权限Int4非空10表名清洗计划主键ID序号字段名称字段说明类
- 温馨提示:
1: 本站所有资源如无特殊说明,都需要本地电脑安装OFFICE2007和PDF阅读器。图纸软件为CAD,CAXA,PROE,UG,SolidWorks等.压缩文件请下载最新的WinRAR软件解压。
2: 本站的文档不包含任何第三方提供的附件图纸等,如果需要附件,请联系上传者。文件的所有权益归上传用户所有。
3.本站RAR压缩包中若带图纸,网页内容里面会有图纸预览,若没有图纸预览就没有图纸。
4. 未经权益所有人同意不得将文件中的内容挪作商业或盈利用途。
5. 装配图网仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对用户上传分享的文档内容本身不做任何修改或编辑,并不能对任何下载内容负责。
6. 下载文件中如有侵权或不适当内容,请与我们联系,我们立即纠正。
7. 本站不保证下载资源的准确性、安全性和完整性, 同时也不承担用户因使用这些下载资源对自己和他人造成任何形式的伤害或损失。
