 智能计算实验报告
智能计算实验报告

《智能计算实验报告》由会员分享,可在线阅读,更多相关《智能计算实验报告(12页珍藏版)》请在装配图网上搜索。
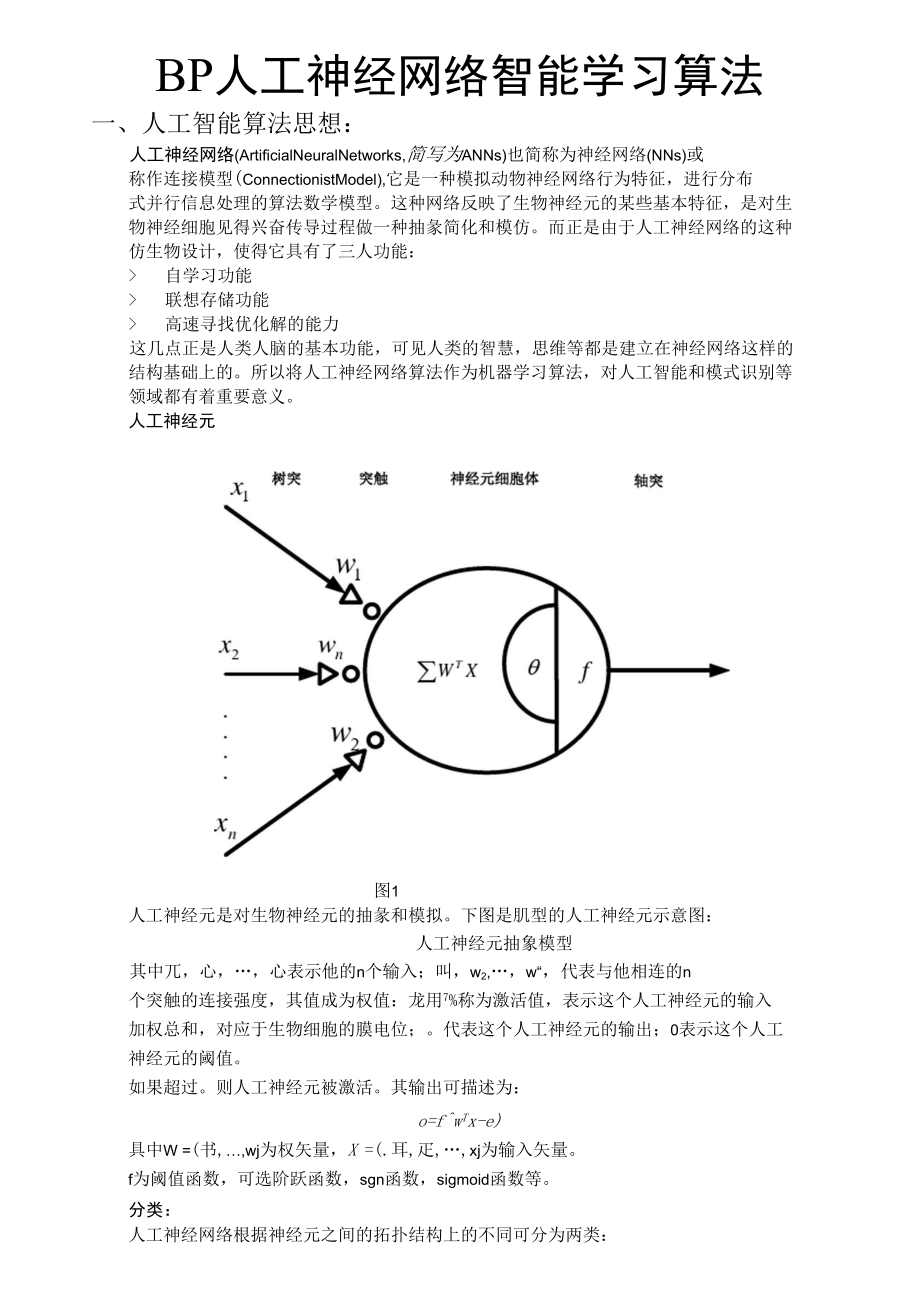
1、图1BP人工神经网络智能学习算法一、人工智能算法思想:人工神经网络(ArtificialNeuralNetworks,简写为ANNs)也简称为神经网络(NNs)或 称作连接模型(ConnectionistModel),它是一种模拟动物神经网络行为特征,进行分布 式并行信息处理的算法数学模型。这种网络反映了生物神经元的某些基本特征,是对生 物神经细胞见得兴奋传导过程做一种抽彖简化和模仿。而正是由于人工神经网络的这种 仿生物设计,使得它具有了三人功能: 自学习功能 联想存储功能 高速寻找优化解的能力这几点正是人类人脑的基本功能,可见人类的智慧,思维等都是建立在神经网络这样的 结构基础上的。所以将人
2、工神经网络算法作为机器学习算法,对人工智能和模式识别等 领域都有着重要意义。人工神经元人工神经元是对生物神经元的抽彖和模拟。下图是肌型的人工神经元示意图:人工神经元抽象模型其中兀,心,心表示他的n个输入;叫,w2,,w“,代表与他相连的n 个突触的连接强度,其值成为权值:龙用7%称为激活值,表示这个人工神经元的输入 加权总和,对应于生物细胞的膜电位;。代表这个人工神经元的输出;0表示这个人工 神经元的阈值。如果超过。则人工神经元被激活。其输出可描述为:o=fwTx-e)具中W =(书,wj为权矢量,X =(.耳,疋,xj为输入矢量。f为阈值函数,可选阶跃函数,sgn函数,sigmoid函数等。
3、分类:人工神经网络根据神经元之间的拓扑结构上的不同可分为两类: 分层网络 相互连接型网络其中分层网络可以细分为三种互联形式: 简单的前向网络 具有反馈的前向网络层内有相互连接的前向网络二、BP 人工神经网络算法:-1BP神经网络是一种具有三层或三层以上的多层神经网络,每层都有若干个神 经元组成,前一级的神经元和每一个后一级的神经元依次连接,其神经元和 网络结构示意图如下:/(*)图2 BP网络神经元输入模式误基反传(学习算法)输入层隐禽层信息流输出层图3 BP网络示意图BP神经网络按有导师的学习方式进行训练,当一学习模式提供给网络后,神经元的激 活值输入层经各中间层向输出层传播,在输出层的各神
4、经元输出对应于输入模式的网络 响应。然后按减少目标输出与实际输出误差的原则,从输出层经各中间层,最后回到输 入层依次修改连接权,随着连接权的不断修正,输出结果的正确率也不断提高。因此 BP神经网络算法称为“误差逆传播算法”。设计BP网络所要考虔的因素: 网络的层数:增加层数能提高精度,但同时会将网络复杂化人大加人迭代时间,所 以一般通过增加每层含有的神经元数来提高精度,在精度要求的范闱内要尽量减少 层数 隐含层的神经元:一般选取输入层节点数的两倍加上一点裕量作为隐含层神经元的 数量。 初始权值的选取:初始权值太人太小都影响学习速度,一般取(-1 1)之间的随 机数也可取(-2.4/n,2.Vn
5、)之间的随机数。 学习速率:学习速率决定每一次循坏训练中所产生的权值变化量。太人,系统不稳 定,太小,系统收敛慢。通常选0.1-0.8o 期望误差的选取:与隐含层的神经元数量相关联。三、梯度下降BP神经元网络算法流程:算法流程图如F:具体步骤:1)确定参数a确定输入向量X; 输入量为X二比,,了(输入层神经元为n个)。b. 确定输出量Y和希望输出量0:输出向量为丫 =比,比,,儿输出层神经元为q个)。希望输出向量O二h。,,勺了。c. 确定隐含层输出向量B:隐含层输出向量为二.b2, -bp (隐含层单元数为p)。隐含层连接权初始化值:= wjY.wj2,,,,旳” F , j = 1,2,
6、o输出层连接权初始化值:匕,F,k = ,2,q 2)输入模式顺传播:a. 计算隐含层各神经元的激活值片:911=1式中VV.为隐含层连接权,0为隐含层单元的阈值。激活函数采用S型函数,即f(x)=1 + e科(一 x)b. 计算隐含层j单元的输出值。将上面的激活值代入激活函数中可得隐含层j单元的 输出值为:bj = f (s)=i + e(工叫兀(=1其中阈值0与“ 一样的被不断修改。C计算输出层第k个单元的激活值:P归=工 巧-q j=d.计算输出层第R个单元的实际输出值儿:= f(.sk =1,2,g)式中V,.为隐含层到输出层的权值;乞输出单元阈值/(Q为S型激活函数。3) 输出误差的
7、你传播当实际输出与目标输出的误差大于要求的误差范I韦I时,就要依次一层层对BP网络 的参数进行更改:a.输出层校正误差为:心=(勺 一yk)yk(1儿)伙=12,q)式中儿为实际输出,勺为希望输出;b.隐含层各单元的校正误差为:_k=L_c. 输出层至隐含层连接权和输出层阈值的校正屋为:vkj = adk-bj2 =adk式中为隐含层J单元的输出,/为输出层的校正误差,G为学习系数d. 隐含层至输入层的校正量为:叫=0勺兀 0/ = P-ej勺为隐含层丿单元的校正误差,0为学习系数,00收敛速度慢 存在局部极小点问题有动量的梯度下降法:梯度下降法在修正权值时,只是按照K时刻的负梯度方向修正,并
8、没有考虑到以前积累 的经验,即以前的梯度方向,从而使得学习过程发生震荡,收敛缓慢。为此可采用如下算法进行改进:Wji a +1)=力(0 + (1 一 a)d (0 + ad(t-1)式中,d(f)表示/时刻的负梯度;为学习速率;6? e 0,1是动量因子,当a = 0时, 权值修正只与当前负梯度有关当a二1时,权值修正就完全取决于上一次循环的负梯度 了。这种方法实际上相当于给系统加入了速度反馈,引入了阻尼项从而减小了系统震荡, 从而改善了收敛性。有自适应1的梯度下降法:由于学习速率对于训练的成功与否有很人的影响,而且合理的学习速率将会缩短训练的 时间,由此可以想到在训练的不同阶段改变梯度下降
9、法中的学习参数,从而获得更好的 训练效果,这就有了自适应1的梯度卞降法。以上两种改进方法还可以同时使用用以更好的改进BP网路的训练过程。五、程序实现:Matlab程序代码如下:P二123;% T为目标矢量226;%创建一个新的前向神经网络net=newff(minmax(P),5,l/,logsig7logsig,/,traingd,);%当前输入层权值和阈值inputweights二netW1,1;inputbias二net. bl;%当前网络层权值和阈值layerWeights=net.LW2,l;layerbias 二n et.b2;%设置训练参数n et.trainParam.show
10、 = 50;n et.trainParamr = 0.05;n et.trainParam.me = 0.9;n et.trainParam.epochs = 10000;n et.trainParam.goal = le-3;% 调用TRAINGDM算法训练BP网络net,tr二train(netRT);%对BP网络进行仿真A = simfnetP)%计算仿真误差E = T-AMSE=mse(E)x=2/3sim(net,x)改变函数newff中控制训练方式的参数traingd-nf以得到不同训练方法的训练结果。 其中:traingd为梯度F降法traingdm1为有动量的梯度卞降法rain
11、gda*为有自适应lr的梯度下降法traingdx1为有动量加自适应lr的梯度下降法运行结果:1阈值函数采用双logsig函数则网络结构为:1.1梯度下降法net=newff(minmax(P)/5/l/,logsig,/,logsig,traingdl);结果为:ProgressEpoch:010000 iterationsTime:0:01:29Performance:10.719.00Gradient;1.000.00149Validation Checks:00100000.001001.00e-1061.2有动量的梯度下降法 net=newff(minmax(P)45/l/,logs
12、ig,/,logsig,traingdm,); 结果为:ProgressEpoch:010000 iterations10000Time:0:01:31Perfo rrnn ce:13.69.000.00100Gradient!1.000.00135 JB1.00e-10Validation Checks:006与采用梯度卜降法时的情况相同收敛到MSE=9的地方了可见梯度很快趋于零,速度比中的方法快,这体现了加入动量对提高收敛速度的作 用,但是提供收敛速度并不能使系统跳出局部最小值。1.3有自适应lr的梯度下降法 net=newff(minmax(P)45/l/,logsig,/,logsig
13、,traingdal);结果为:Epoch:Time:Performance:Gradient:Validation Checks;可见只用了 468次迭代MSE就满足要求了。Gradient = 9.5247e-011. at epoch 468梯度一直稳定卜降468 Epochs学习率最后变得很人1.4有动量加自适应lr的梯度下降法net=newff(minmax(P)/5/l/,logsig,/,logsig,/,traingdx,);结果为:Gradient = 9.9387e-011, at epoch 461梯度一直减小趋近于零学习率后来变得很人由以上结果可得出结论: 梯度下降法可
14、能收敛于局部极小值加入向量可以使得网络梯度下降更快,但无法跳出局部极小值区域 改变学习速率对改善网络训练有很大帮助,可以跳出局部极小值区域2阈值函数采用tansig (正切s型传递函数)和purelin (线性传递函数)函数 则网络结构为:Neural Network2.1梯度下降法net=newff(minmax(P), 5,1,r tansig1r 1purelin1z 11raingd1); 结果为:ProgressEpoch:074 iterations10000Time:I0:00:01Perfo rrnance:18.30.0009100.00100Gradient;1.000.0
15、427|1.00e-10Validation Checks:0| 0674次训练后收敛2.2有动量的梯度下降法net=newff(minmax(P), 5,1,r tansig1r 1purelin1z 11raingdm1); 结果为:Epoch:Time:Performance:Gradient:Validation Checks;newff(minmax(P), 5,1,1 tansig1r 1purelin1z 11raingda1); 结果为:ProgressEpoch:Time;Perfo r mance:Gradient:Validation Checks:32次迭代就训练完成了
16、。梯度一直平滑减小学习率一直平滑增人2.4有动量加自适应lr的梯度下降法newff(minmax(P), 5,1,tansigz r fpurelinz/91raingdxz); 结果为:gradientKXooo%O2Gradient = 0.047544, at epoch 401 1 1 1 1 1 1 -1 1 1 1 1 1 1由以上实验得出结论: 加入向量并不是在任何情况下都会加快系统收敛速度的,还町能使得系统迭代次数 增加不同的阈值函数对于训练的速度,收敛性有非常人的影响,所以在设计神经网络是 要尽量选择合适的阈值函数已达到快速收敛和高精度的特性。六、总结与展望BP神经网络数学意义明确,步骤分明,理论上可以实现多为单位立方体/T到/T得映 射,够逼近任何有理函数,有着非常广泛的应用前景。但是这个方法也有很多的不足, 比如试验中观察到的无法跳出局部极值的问题,采用改变学习率的方法町以克服这个缺 点,同时如果不改变学习率,我觉得也可以用模拟退火的方法跳出局部极值区域,虽然 很骨能效果没有改变学习率好,但也值得尝试。参考文献1 mat lab中文论坛mat lab神经网络30个案例分析北京航空航天人学出版社2 杨淑莹模式识别与智能计算-matlab技术实现电子工业出版社智能计算作业学号:3110038000专业班级:硕037班姓名:
- 温馨提示:
1: 本站所有资源如无特殊说明,都需要本地电脑安装OFFICE2007和PDF阅读器。图纸软件为CAD,CAXA,PROE,UG,SolidWorks等.压缩文件请下载最新的WinRAR软件解压。
2: 本站的文档不包含任何第三方提供的附件图纸等,如果需要附件,请联系上传者。文件的所有权益归上传用户所有。
3.本站RAR压缩包中若带图纸,网页内容里面会有图纸预览,若没有图纸预览就没有图纸。
4. 未经权益所有人同意不得将文件中的内容挪作商业或盈利用途。
5. 装配图网仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对用户上传分享的文档内容本身不做任何修改或编辑,并不能对任何下载内容负责。
6. 下载文件中如有侵权或不适当内容,请与我们联系,我们立即纠正。
7. 本站不保证下载资源的准确性、安全性和完整性, 同时也不承担用户因使用这些下载资源对自己和他人造成任何形式的伤害或损失。
