 apacheTez调研笔记
apacheTez调研笔记

《apacheTez调研笔记》由会员分享,可在线阅读,更多相关《apacheTez调研笔记(16页珍藏版)》请在装配图网上搜索。
1、1. 什么是Apache TezTez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。Tez并不直接面向最终用户它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。Tez项目的目标是支持高度定制化,这样它就能够满足各种用例的需要,让人们不必借助其他的外部方式就能完成自己的工作。它直接源于MapReduce框架,核心思想是将Map
2、和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。总结起来,Tez有以下特点:1) 运行在yarn上;2) 适用于DAG(有向图)应用(可与hive和pig结合);3) 具有表现力的数据流APITez团队希望通过一套富有表现力的数据流定义API让用户能够描述他们所要运行计算的有向无环图 (DAG)。为了达到这
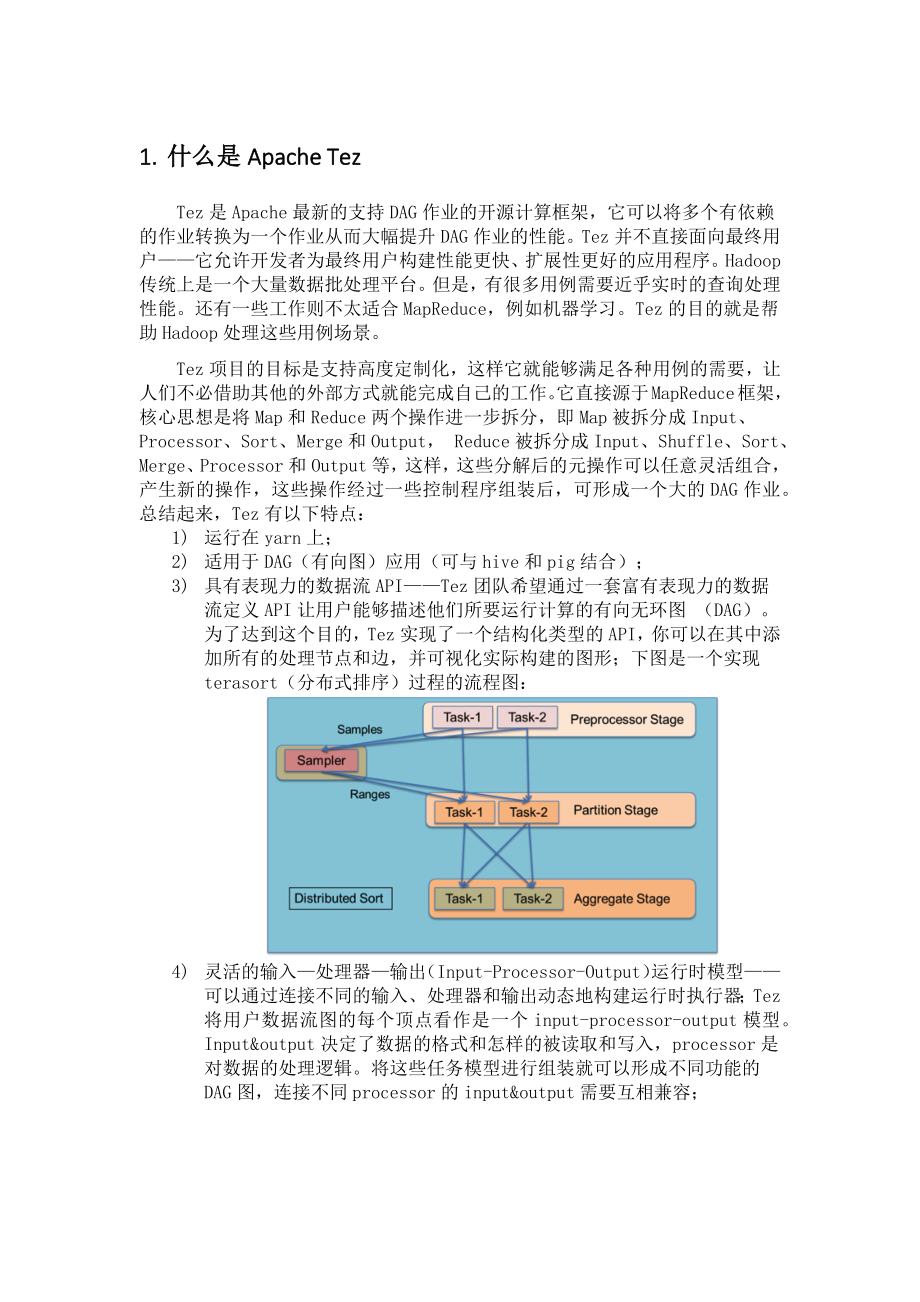
3、个目的,Tez实现了一个结构化类型的API,你可以在其中添加所有的处理节点和边,并可视化实际构建的图形;下图是一个实现terasort(分布式排序)过程的流程图:4) 灵活的输入处理器输出(Input-Processor-Output)运行时模型可以通过连接不同的输入、处理器和输出动态地构建运行时执行器;Tez将用户数据流图的每个顶点看作是一个input-processor-output模型。Input&output决定了数据的格式和怎样的被读取和写入,processor是对数据的处理逻辑。将这些任务模型进行组装就可以形成不同功能的DAG图,连接不同processor的input&output
4、需要互相兼容;5) 数据类型无关性仅关心数据的移动,不关心数据格式(键值对、面向元组的格式等,mr需要指定map和reduce的输入输出格式);6) 简单地部署Tez完全是一个客户端应用程序,它利用了YARN的本地资源和分布式缓存;7) DAG图在运行时的优化和重新配置分布式数据处理是具有动态的特性,不能执行前提前预知并选出最有的优化策略。Tez可以在执行过程中通过收集tasks的信息更改数据流图。例如下图,运行时,当获知数据量有10GB的时候,自动将reducer的数量进行更改。Tez于2014-07-16成为apache顶级项目,目前最新的稳定版本是0.7.0,最新版本是0.8.1-bet
5、a版,目前我们平台HDP2.3采用的是0.7.0。Apache当前有顶级项目Oozie用于DAG作业设计,但Oozie是比较高层(作业层面)的,它只是提供了一种多类型作业(比如MR程序、Hive、Pig等)依赖关系表达方式,并按照这种依赖关系提交这些作业,而Tez则不同,它在更底层提供了DAG编程接口,用户编写程序时直接采用这些接口进行程序设计,这种更底层的编程方式会带来更高的效率,举例如下:传统的MR(包括Hive,Pig和MR程序)。假设有四个有依赖关系的MR作业(1个较为复杂的Hive SQL语句或者Pig脚本可能被翻译成4个有依赖关系的MR作业)或者用Oozie描述的4个有依赖关系的作
6、业,运行过程如下图左边所示(其中,绿色是Reduce Task,需要写HDFS),采用tez的示意图如右边所示。通过上面的例子可以看出,Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能。原来的mapreduce作业需要执行多次的hdfs的读写。2. Tez的优化2.1. 当前YARN框架存在的问题(1)作业启用一个独立的ApplicationMasterMRv1中所有作业公用一个作业追踪器JobTracker,当JobTracker出现故障是 ,整个系统将不可用,且所有作业将运行失败。与MRv1不同,YARN中每个作业启用一个独
7、立的作业追踪器ApplicationMaster,解决了MRv1中单点故障和扩展瓶颈问题。但这种方式引入一个新的问题:作业延迟较大,即每个作业首先要申请资源启动一个ApplicationMaster后,才可以正式启动作业,也就是说,较MRv1中的作业运行过程,YARN作业将耗费更多的计算资源和产生更长的运行延迟,这不利于运行小作业和DAG作业,尤其是DAG作业(如Hive SQL和Pig产生的DAG作业),将需要更多的计算资源。(2)资源无法重用在MRv1中,用户可为自己的作业设置是否启用JVM重用功能,如果启用该功能,则同一个JVM可运行多个任务,从而降低作业延迟提高作业效率。在YARN M
8、RAppMaster(MRAppMaster是MapReduce计算框架的ApplicationMaster)中,MRAppMaster总是为未运行的任务申请新的资源(Container),也就是时候,任务运行完成后便会释放对应的资源,并为接下来运行的任务重新申请资源(Container),而不会向MRv1那样重用资源(Container)。2.2 Apache Tez中的优化技术为了克服当前YARN存在的问题,Apache Tez提出了一系列优化技术,其中值得一说的是ApplicationMaster缓冲池、预先启动Container和Container重用这三项技术。(1)Applicat
9、ionMaster缓冲池在Apache Tez中 ,用户并不是直接将作业提交到ResouceManager上,而是提交到一个 叫AMPoolServer的服务上。该服务启动后,会预启动若干个ApplicationMaster,形成一个ApplicationMaster缓冲池,这样,当用户提交作业时,可通过AMPoolServer直接将作业提交到这些ApplicationMaster上。这样做的好处是,避免了每个作业启动一个独立的ApplicationMaster。在Apache Tez中,管理员可采用参数tez.ampool.am-pool-size和tez.ampool.max.am-poo
10、l-size配置ApplicationMaster缓冲区中最小ApplicationMaster个数和最大ApplicationMaster个数。(2)预先启动ContainerApplicationMaster缓冲池中的每个ApplicationMaster启动时可以预先启动若干个Container,以提高作业运行效率。管理员可通过参数yarn.app.mapreduce.am.lazy.prealloc-container-count设置每个ApplicationMaster预启动container的数目。(3) Container重用每个任务运行完成后,ApplicationMaster
11、不会立即释放其占用的container,而是将其分配给其他未运行的任务,从而达到资源(Container)重用的目的。管理员可通过参数yarn.app.mapreduce.am.scheduler.reuse.enable指定是否启用Container重用功能,通过参数yarn.app.mapreduce.am.scheduler.reuse.max-attempts-per-container设置每个container重用次数。3. Tez on HDP在HDP2.3版本中已经集成了Tez,在首页右边能看到Tez的任务视图页面。点击每个Tez的任务,能查看到DAG信息和所有对任务的描述。如下
12、是执行hive两表join的任务,执行语句如下:分别是表clc_test join clc_test2和clc_test2 join clc_test,DAG图如下: 图中,map1、map2不是说这里只有两个map,他们是DAG处理节点(vertex)的名称(节点Vertex的名称可以在程序中随便定义),根据输入数据量或者配置的不同,每个处理节点可以并行运行多个任务。除节点外,在DAG图中还可以看到连接两个vertex的边的信息,看下图,Map2 到 map1的边(edge)用来连接两个vertex,可以在DAG图中查看输入和输出的类型为Unordered*,map2的作用实质就是把被joi
13、n的表输入到map1中去做join运算,所以数据并不需要排序。另外由于数据量少,从map2到map1的数据移动类型(Data movement type)为broadcast,这个等同于mr里面的map join。下面再看一个更复杂的select语句:DAG图如下图所示,map1和map2负责join,reducer3负责distinct和group by。在HDP上通过yarn jar 运行mr和tez自带的wordcount案例,比较两个的运行时间,发现tez的整体运行时间为34秒,mr为50秒;任务的application master和container都启动之后执行数据处理的时间,t
14、ez为6秒,mr要31秒。启动的时候,tez多了一步DAG的启动,而且启动就花了15秒,4. Tez的实现Tez对外提供了6种可编程组件,分别是:(1)Input:对输入数据源的抽象,它解析输入数据格式,并吐出一个个Key/value;(2)Output:对输出数据源的抽象,它将用户程序产生的Key/value写入文件系统;(3)Paritioner:对数据进行分片,类似于MR中的Partitioner;(4)Processor:对计算的抽象,它从一个Input中获取数据,经处理后,通过Output输出;(5)Task:对任务的抽象,每个Task由一个Input、Ouput和Processor
15、组成;(6)Maser:管理各个Task的依赖关系,并按顺依赖关系执行他们。除了以上6种组件,Tez还提供了两种算子,分别是Sort(排序)和Shuffle(洗牌),为了用户使用方便,它还提供了多种Input、Output、Task和Sort的实现。为了展示Tez的使用方法和验证Tez框架的可用性,Apache在YARN MRAppMaster基础上使用Tez编程接口重新设计了MapReduce框架,使之可运行在YARN中。为了减少Tez开发工作量,并让Tez能够运行在YARN之上,Tez重用了大部分YARN 中MRAppMater的代码,包括客户端、资源申请、任务推测执行、任务启动等。Tez
16、 API包括以下几个组件:l 有向无环图(DAG)定义整体任务。一个DAG对象对应一个任务。l 节点(Vertex)定义用户逻辑以及执行用户逻辑所需的资源和环境。一个节点对应任务中的一个步骤。l 边(Edge)定义生产者和消费者节点之间的连接。边需要分配属性,对Tez而言这些属性是必须的。下面是一些边的属性:n 数据移动属性,定义了数据如何从一个生产者移动到一个消费者,三种方式:One-To-One,Broadcast,scatter- Gather。n 调度(Scheduling)属性(顺序(Sequential)或者并行(Concurrent),帮助我们定义生产者和消费者任务之间应该在什么
17、时候进行调度。n 数据源属性,定义任务输出内容的生命周期或者持久性,让我们能够决定何时终止。总共分3种:u Persisted: Output will be available after the task exits. Output may be lost later on.(任务结束output才可用)u Persisted-Reliable: Output is reliably stored and will always be available.(output存储到一个地方并且一直可用)u Ephemeral: Output is available only while the
18、 producer task is running.(当edge的生产者运行的时候output才可用)下图为一个利用DAG API定义的一个数据流程,总共定义了5个vertex,4个edge。5. Tez的扩展性总体来看,Tez为开发人员提供了丰富的扩展性以便于让他们能够应对复杂的处理逻辑。这可以通过下面一个hive on tez的示例来说明。让我们看看这个经典的TPC-DS查询模式,在该模式中你需要将多个维度表与一个事实表连接到一起。大部分优化器和查询系统都能完成该图右上角部分所描述的场景:如果维度表较小,那么可以将所有的维度表与较大的事实表进行广播连接(map join),这种情况下你可以
19、在Tez上完成同样的事情。但是如果这些广播包含用户自定义的、计算成本高昂的函数呢?此时,你不可能都用这种方式实现。这就需要你将自己的任务分割成不同的阶段,正如该图左边的拓扑图所展示的方法。第一个维度表与事实表进行广播连接,连接的结果再与第二个维度表进行广播连接。第三个维度表如果太大了就不再进行广播连接,可以选择使用shuffle连接,Tez能够非常有效的实现这个拓扑结构。使用Tez完成这种类型的Hive查询的好处包括:l 提供了全面的DAG支持,同时会自动地在集群上完成大量的工作,因而它能够充分利用集群的并行能力;正如上面所介绍的,这意味着在多个MR任务之间不需要从HDFS上读/写数据,通过一
20、个单独的Tez任务就能完成所有的计算。l 它提供了会话和可重用的容器,因此延迟低,能够尽可能地避免重组。6. 代码解析下面分析一下tez-examples-0.7.0.2.3.0.0-2557.jar里wordcount的源码。Tez的wordcount的DAG图:如上图所示,节点tokenizer等同于map,节点Summation等同于reduce。首先在类中定义2个vertex和job的总输入输出的名称:然后创建DAG:我们来看下两个vertex的类定义,TokenProcessor类(类似于map):SumProcessor类(类似于reduce):编写完DAG逻辑之后,再写一个run
21、Job的方法,运行createDAG并runDag:以上是编写一个Tez主要要做的事情,只要定义好处理数据的逻辑(也就是DAG的vertex)并且组织好DAG就行,剩下代码的可以直接拷贝复制。程序的执行,我们从类的继承开始看起:在例子中,wordcount继承了TezExampleBase,TezExampleBase里面封装了一些公共的方法,当然也可以不用继承TezExampleBase类,把方法都写到WordCount类中。TezExampleBase继承了Configured并实现了Tool接口,这跟mr的继承一样。WordCount类中main函数运行与mr也一样:ToolRunner调用TezExampleBase的run(String args)函数:TezExampleBase中的run函数如下所示,调用_execute函数:_execute调用WordCount的runJob函数:在runJob中创建DAG,并且执行runDag函数。函数调用的关系图如下:源代码如下:
- 温馨提示:
1: 本站所有资源如无特殊说明,都需要本地电脑安装OFFICE2007和PDF阅读器。图纸软件为CAD,CAXA,PROE,UG,SolidWorks等.压缩文件请下载最新的WinRAR软件解压。
2: 本站的文档不包含任何第三方提供的附件图纸等,如果需要附件,请联系上传者。文件的所有权益归上传用户所有。
3.本站RAR压缩包中若带图纸,网页内容里面会有图纸预览,若没有图纸预览就没有图纸。
4. 未经权益所有人同意不得将文件中的内容挪作商业或盈利用途。
5. 装配图网仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对用户上传分享的文档内容本身不做任何修改或编辑,并不能对任何下载内容负责。
6. 下载文件中如有侵权或不适当内容,请与我们联系,我们立即纠正。
7. 本站不保证下载资源的准确性、安全性和完整性, 同时也不承担用户因使用这些下载资源对自己和他人造成任何形式的伤害或损失。
